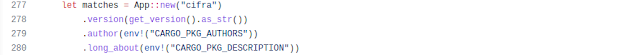En mi artículo sobre GitHub Actions vimos que se pueden crear flujos de trabajo completo simplemente usando unidades ya hechas, denominadas Actions, que se pueden encontrar en el GitHub Marketplace.
En mi artículo sobre GitHub Actions vimos que se pueden crear flujos de trabajo completo simplemente usando unidades ya hechas, denominadas Actions, que se pueden encontrar en el GitHub Marketplace.
En ese marketplace puedes encontrar muchísimas Actions listas para ser usadas, pero probablemente en algún momento te veas en la necesidad de hacer algo para lo que no haya aún Action alguna en el marketplace. En esos caso podrías usar tus propios scripts. De hecho, en aquel artículo ya utilicé un script (./ci_scripts/get_version.py) en la sección "Compartir datos entre pasos y flujos". El problema con ese enfoque es que si quieres hacer las mismas tareas en otro proyecto tendrás que copiar los scripts entre proyectos y adaptarlo. Lo suyo en realidad es transformar los scripts en Actios que puedan ser fácilmente reutilizables no sólo en tus proyectos sino también en los de otros desarrolladores.
Todas las Actions que se pueden encontrar en el marketplace se han desarrollado usando uno de los métodos que voy a explicar aquí. En realidad, si entrar en la página del marketplace de cualquier Action encontrarás un enlace, a mano derecha, al repositorio de git de esa Action, por lo que puedes analizar su código y ver cómo funciona.
Hay tres métodos principales para crear tu propio Action para GitHub:
- Composite Actions: Son las más sencillas y rápidas de desarrollar, pero tienen que cumplir la condición de que se basen en un script autosuficiente que no requiera que se instalen dependencias adicionales. Es decir, deben ser capaces de funcionar con lo que un Linux estándar ofrezca de base.
- Docker Actions: Si tu Action va a necesitar la instalación de alguna dependencia para funcionar, entonces tendrás que usar esta opción.
- Javascript Actions: Bueno... es cierto que también puedes desarrollar tus Actions usando javascript, pero aborrezco ese lenguaje, así que no voy a desarrollar esta opción en este artículo.
El problema con las dependencias de las Actions es que pueden contaminar el entorno donde se vaya a usar la Action. Si no tienes cuidado, y optas por una Composite Action instalando dependencias, estas pueden colisionar con la de la app que quieras compilar con la Action. Esa es la razón por la que resulta imprescindible encapsular nuestra Action y sus dependencias para que sean independientes del entorno en el que compilemos la app. Por supuesto, esto no será un problema si el propósito explícito de la Action es precisamente instalar algo para preparar el entorno. Hay Actions, por ejemplo, para instalar y configurar Pandoc para usarlo en el workflow. El problema surge cuando se supone que el propósito explícito de tu Action es algo ajeno a la instalación de paquete alguno (por ejemplo, copiando ficheros) y sin embargo acaba instalando algo de manera inadvertida comprometiendo el entorno del flujo de trabajo. Por eso, lo mejor es que cuando necesites instalar algo para tu Action lo hagas en un contenedor de Docker y hagas que el script de tu Action se ejecute en ese contenedor de Docker, de manera que sus dependencias sean completamente independientes de los paquetes instalados en el entorno del flujo.
Composite Actions
Si a tu Action le basta con un puñado de comandos de Bash o con un script de Python que utilice exclusivamente la librería estándar, entonces las Composite Actions son tu opción.
Como ejemplo de una Composite Action, vamos a revisar cómo funciona mi Action
rust-app-version. Esa Action busca un fichero de configuración Cargo.toml y lee qué versión consta en él para la aplicación de Rust. La cadena de esa versión es precisamente la salida del Action, de manera que puedas usar esa cadena en otros puntos de tu flujo, por ejemplo para etiquetar una nueva
release en GitHub. Esta Action en concreto sólo usa módulos disponibles en la distribución estándar de Python. Es decir, que no tiene que instalar nada en la máquina virtual de GitHub Actions (el runner). Es cierto que si analizas el repositorio de rust-app-version verás un fichero requierements.txt pero este sólo es para instalar paquetes necesarios para el testeo unitario de la Action (recuerda que una Action no deja de ser una app más).
Para tener tu propia Action, lo primero es crear un repositorio de GitHub para albergarlo. Allí podrás ubicar los poquitos ficheros que se necesitan en realidad para hacer funcionar tu Action.
En la raíz del repositorio debes crear un fichero que se llame "action.yml". Este fichero es realmente importante ya que es el que le da forma a tu Action. Debes conseguir que tus usuarios puedan pensar en tu Action como si fuera una caja negra, como si fuera un módulo en el que metes entradas (inputs) y recibes salidas (outputs). Precisamente esos inputs y outputs se definen en el fichero action.yml.
Los outputs son algo diferentes, dado a que deben referirse al output de un caso específico de tu Action:
En la última sección especificamos que esta Action tendrá un único output llamado "app_version" y que ese output será el output llamado "version" de un paso con el valor de id "get-version".
Esos inputs y outputs definen lo que tu Action consume y ofrece, es decir, lo que tu Action hace. El cómo lo hace tu Action se define bajo la etiqueta "runs:". Ahí es donde defines que tu Action es una composite, en la que vas a llamar a una secuencia de pasos. Este ejemplo en particular sólo tiene un paso, pero puedes tener todos los que necesites:
Fíjate que en la línea 22 es donde el paso recibe el id "get-version". Ese nombre es importante para poder referirse a este paso en particular desde la configuración de los outputs.
La línea 24 es donde se ejecuta el comando. Aquí sólo he ejecutado un comando, pero si necesitases ejecutar varios comandos dentro del mismo paso bastaría con usar una barra después de la etiqueta run: "run: |". De esa manera, señalas que las siguientes líneas, que se indenten bajo la etiqueta "run:", son líneas separadas de comandos que deben ser ejecutadas secuencialmente.
El comando de la línea 24 también es interesante por 3 cosas:
- Llama a un script situado en el repositorio de nuestro Action. Para referirse a la raíz del repositorio del Action hay que usar la variable de entorno github.action_path. Lo bueno es que aunque nuestro script esté en el repositorio del Action GitHub lo ejecuta de manera que tenga visibilidad del repositorio del flujo de trabajo desde el que se llama a la Action. Nuestro script (el del Action) verá los ficheros del repositorio del flujo como si hubiese sido ejecutado desde su raíz.
- Al final de la línea se puede ver cómo se pueden utilizar los inputs, a través del contexto inputs.
- Lo más raro de esa línea es probablemente como configuras el output del paso. Para fijar el output de un paso de bash debes hacer echo "::set-output name=<ouput_name>::<output_value>". En este caso, name es version y su valor es lo que get_version.py imprime en la consola. Ten en cuenta que output_name se usa para recuperar el output, una vez que el paso finaliza, mediante ${{ steps.<id>.outputs.<output_name> }}, en este caso ${{ steps.get_version.outputs.version }}
Aparte de eso, no hay más que configurar los metadatos del Action. Para eso, no se necesitan más que unas pocas líneas:
Ten en cuenta que el valor de "
name:" es el nombre que tendrá tu Action en el marketplace. El otro parámetro "
description:" es la explicación corta que se mostrará junto al nombre en los resultados de las búsquedas del marketplace. Por último, la etiqueta "branding:" sirve para configurar el icono (de los disponibles en la suite
Feather icon) y el color de este que representarán a nuestra Action en el marketplace.
Con esas 24 líneas en el fichero action.yml y tu script en su ruta respectiva ( en este caso la subcarpeta
rust_app_version/ ), ya puedes usar tu Action. Sólo necesitas pulsar el botón que aparecerá en tu repositorio para publicar el Action en el marketplace. De todos modos, antes de lanzarte a hacerlo te recomiendo que te leas este artículo hasta el final porque tengo algunos consejos que sospecho que te serán útiles.
Una vez publicada, tu Action ya será visible para el resto de los usuarios de GitHub. Además, se creará automáticamente
la página de tu Action en el marketplace. Para usar una Action como esta lo único que tienes que hacer es incluir en tu flujo una configuración como la siguiente:
Docker actions
Si tu Action necesitase instalar alguna dependencia entonces deberías empaquetarla dentro de un contenedor de docker. De esa manera las dependencias de la Action no se mezclarán con las dependencias del flujo desde el que se llame a la Action.
Como ejemplo de una Docker Action, vamos a revisar cómo funciona mi Action
markdown2man. Esta Action coge un fichero README.md y lo convierte en un manpage. Con esta Action no necesitas mantener dos fuentes diferentes para la documentación de cómo usar tu aplicación de consola. En vez de eso, puedes usar un único fichero README.md para documentar el uso de tu aplicación y generar automáticamente a partir de él el manpage.
Para hacer esa conversión markdwon2man necesita que se instale el paquete Pandoc. Además, Pandoc tiene también sus respectivas dependencias por lo que instalar todo eso en el runner del usuario puede romper su flujo de trabajo. En vez de eso, lo que haremos será instalar esas dependencias en una imagen de docker y ejecutar nuestro script desde esa imagen. Recuerda que docker te permite ejecutar scripts desde el contenedor interactuando con los ficheros del anfitrión del contenedor.
Igual que en el caso de las Composite Action, tendremos que crear un fichero
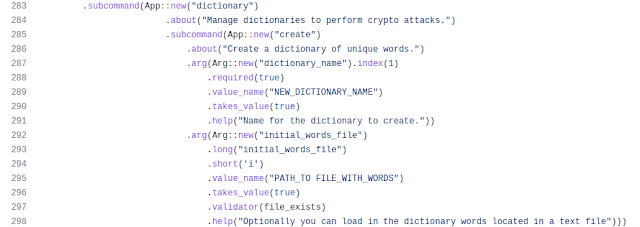
action.yml en la raiz del repositorio del Action. Allí configuraremos nuestros metadatos, los inputs y los outputs tal y como hicimos para las Composite Actions. La diferencia en este caso es que concretamente markdown2man Action no emite output alguno, por lo que esa sección se omite. La sección para "runs:" también es diferente:
En esa sección definimos que esta Action es del tipo docker (en "using:"). Hay dos maneras de usar una imagen de docker en tu Action:
- Generar una imagen específicamente para esa Action y guardarla en el registro de docker de GitHub. En ese caso usaríamos la etiqueta "image: Dockerfile".
- Usar una imagen del registro de DockerHub registry. Para hacer eso hay que usar la etiqueta "image: <dockerhub_user>:<docker-image-tag>".
Si la imagen que vamos a construir estuviera pensada para ser usada sólo en una Action de GitHub yo iría por el primer enfoque (el del Dockerfile). En el caso de markdwon2man elegí la opción del Dockerfile. Cada vez que actualicemos nuestro Dockerfile, GitHub se encargará de de construir una nueva imagen y guardarla en su registro para poder ofrecerla rápidamente a los Actions que hagan uso de esa imagen. Recuerda que un Dockerfile es una especie de receta para "cocinar" una imagen, por lo que los comandos que se incluyan en él solo se ejecutarán cuando se construya la imagen (cuando se "cocine"). Una vez construida la imagen, el único comando que se ejecutará es el que fijemos en la etiqueta "entrypoint" al llamar al contenedor (y pasarle argumentos) con el comando "docker run".
La etiqueta "args:" define los parámetros que se pasarán al script de nuestro contenedor. Probablemente uses alguno de los input de tu Action para pasárselo como parámetro al script del contenedor. Ten en cuenta que, como pasaba con las Composite Actions, los ficheros del repositorio del usuario que llama al Action también son visibles para el contenedor de dicho Action.
Después, fijé los metadatos de la imagen:
Para configurar tu image, por ejemplo para instalar cosas, puedes usar los comandos RUN:
El comando ENV genera variables de entorno que pueden ser utilizados en otros comandos del Dockerfile:
Puedes usar el comando COPY para introducir ficheros de tu repositorio en la imagen. En este caso lo utilicé para copiar el fichero requirements.txt desde el repositorio a dentro de la imagen. Tus scripts se pueden incluir dentro de imagen, desde el repositorio del Action, de la misma manera:
Una vez que copié el script dentro de la imagen, lo hice ejecutable y lo enlacé desde la carpeta /usr/bin para incluirlo en el path del sistema:
Después de eso, se configura el script como el entrypoint de la imagen, de manera que se ejecute en cuanto se arranque la imagen con los argumentos mencionados en la etiqueta "args:" del fichero action.yml.
Puedes probar esa imagen en tu ordenador construyendo la imagen desde el Dockerfile y ejecutándola como un contenedor:
dante@Camelot:~/$ docker run -ti -v ~/your_project/:/work/ dantesignal31/markdown2man:latest /work/README.md mancifra
dante@Camelot:~$
Si el script del contenedor procesa ficheros del repositorio, nos vendrá bien probarlo localmente montando una carpeta de nuestro ordenador con el flag -v. Los dos últimos argumentos del ejemplo (work/README.md y mancifra) son los argumentos que se le pasan al entrypoint.
Y eso es todo. Una vez que lo hayas probado todo ya puedes publicar tu Action y usarla en tus flujos:
Con una llamada como esa, se creará un fichero man llamado cifra.2.gz en una carpeta llamada man. Si la carpeta manpage_folder no existiese, entonces markdown2man la crearía para ti.
Tus Action son código de primera clase
Aunque tus Actions probablemente sean pequeñas, deberías tratarlas como lo harías con una app completa. Ten en cuenta que mucha gente encontrará tus Action a través del marketplace y los incluirá en sus flujos. Un error en tu Action puede romper los flujos de mucha gente, por eso hay que ser diligente y probar tu Action como harías con cualquier otra app.
Por eso, con mis Actions sigo la misma aproximación que en otros proyectos y configuro un flujo de GitHub para ejecutar tests contra cualquier push en la rama staging del repositorio de mi Action. Solo cuando los tests se ejecutan con éxito, se produce el merge automático de la rama staging con la principal y se genera una nueva release de la Action.
- Tests unitarios: Comprueban el script de python en el que se basa markdown2man.

- Tests de integración: Comprueban el comportamiento de markdown2man como Action. Aunque tu Action no se haya publicado aún, la puedes instalar desde un flujo del mismo repositorio (como puedes ver en las líneas 42 a 48). Así que lo que yo hago es llamar al Action precisamente desde la rama staging que estoy probando y uso ese Action con un fichero markdown que tengo preparado en la carpeta de test. si se genera un fichero manpage, entonces el test funcional tiene éxito (línea 53). Tener la oportunidad de probar tu Action contra tu propio repositorio está muy bien, ya que te permite comprobar cómo utilizaría la gente tu Action, sin necesidad de publicarlo.
Además de probarlo, deberías escribir un fichero README.md para tu Action, con el fin de explicar con detalle como usarlo. En ese documento deberían incluir al menos la siguiente información:
- Una descripción de los que hace el Action.
- Los input y outputs obligatorios.
- Los inputs y outputs opcionales.
- Cualquier contraseña que el Action pudiera necesitar que se le facilite.
- Que variables de entorno utiliza el Action.
- Un ejemplo de cómo usar tu Action en un flujo.
Por último, yo añadiría también un fichero LICENSE, explicando los términos legales de uso de tu Action.
Conclusión
El punto fuerte de GitHub Actions es el alto grado de reusabilidad y compartición que promueve. Cada vez que te encuentres repitiendo el mismo conjunto de comandos, será el momento de hacer un Action con esos comandos y compartirlos a través del Marketplace. Si lo haces así obtendrás una pieza de funcionalidad que será mucho más fácil de usar en tus flujos que tirando de copia-pegas de montones de comandos y además estarás contribuyendo a mejorar el marketplace permitiendo que otros se puedan beneficiar del Action que hayas desarrollado.
Gracias a esa filosofía, el GitHub Marketplace ha crecido hasta hospedar una cantidad enorme de Actions, listos para ser usados y para salvarte de implementar una y otra vez la misma funcionalidad por ti mismo.
 Este libro formaba parte de un paquete que sacó hace algún tiempo Humble Bundle, con libros para desarrollar juegos con Unity y con Godot.
Este libro formaba parte de un paquete que sacó hace algún tiempo Humble Bundle, con libros para desarrollar juegos con Unity y con Godot.